Problem Statement: In highly regulated industries such as legal/medical/finance, a 5% error rate due to hallucinations and other non-deterministic computation could be unacceptably expensive.
The current generation Agentic AI conflates code, data, probabilistic structure and computation into a giant matrix. In this note we argue that next‑generation agentic systems should externalize code, data, and structure into graph‑native substrates, where deterministic traversal is composed with probabilistic learning.
In fact, we can argue that this process has already started. Some of the most successful production systems, such as terminal-based coding agents like Claude Code, take a problem, generate code to solve it, and run the generated code. This is already a decomposition: LLM for synthesis, runtime for deterministic execution.
A logical extension of the system is to extend this to data. Instead of memorizing junk facts from half of the public internet in the weights of the model, we use ML to create an externalized version of the data and teach models how to access it. While Text2SQL is a member of this category, we believe that you’ll need something more general to be effective. It’s widely accepted that the model trained on the highest-quality, carefully curated data will win the AI race.
A further application of the same idea is the probabilistic neural network that’s at the heart of every LLM. Non-deterministic computation yields costly mistakes for highly regulated industries like legal, medical, and finance.
These networks exhibit two distinct sources of non-determinism. First, at the input representation stage, tokenizing and embedding the input sequence into fixed-dimensional vectors involves a lossy transformation—the embedding space has finite capacity, so semantically similar inputs may map to nearby (but not identical) representations, introducing ambiguity from the start.
Second, at the computational structure level, interpretability research suggests that as activations flow through the transformer layers, the network performs something akin to probabilistic graph traversal over its learned knowledge representations. Rather than executing a deterministic lookup, the model navigates through overlapping, distributed patterns in weight space, following probabilistic pathways where each layer refines which relational connections are most likely relevant to the query.
Summarizing these observations:
| Input | Structure | Example |
|---|---|---|
| Probabilistic | Probabilistic | Current Generation LLMs |
| Deterministic | Deterministic | Graph Databases |
| Deterministic | Probabilistic | Graph Neural Networks |
| Probabilistic | Deterministic | Bulk Synchronous Processing |
Visualizing with an Example
Let’s consider the query:
Tell me the GDP of the place of which Erdogan is the head
The following diagrams help you visualize the four different ways of implementing this.
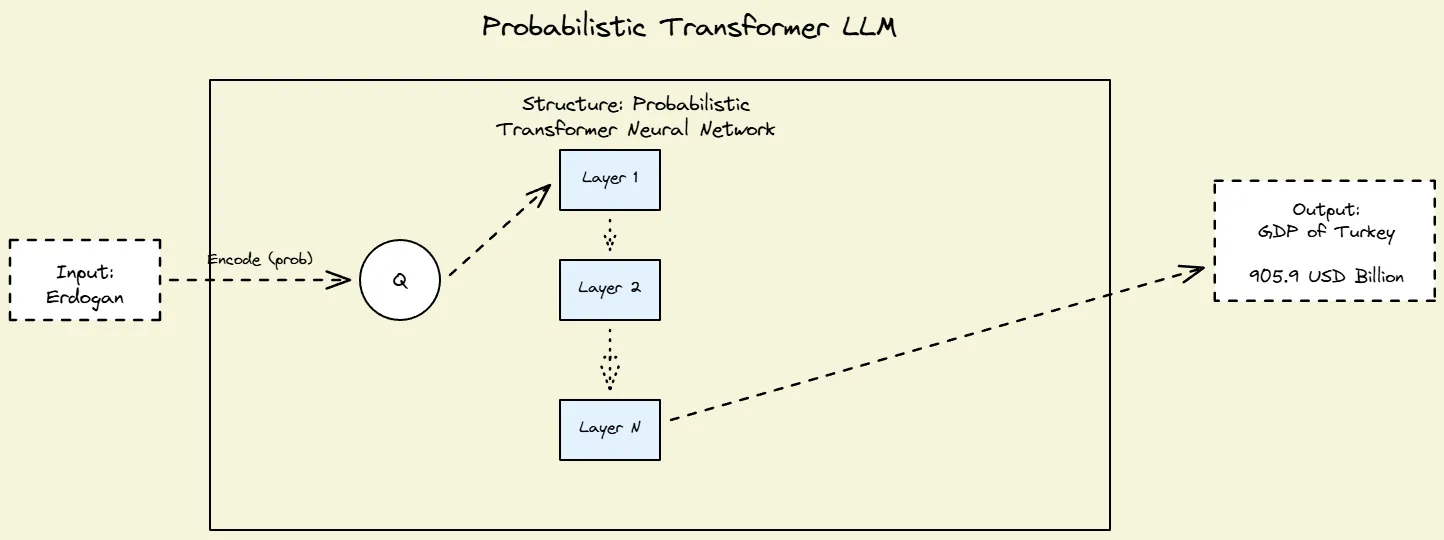 Fig 1: Neural Networks, transformer based LLMs
Fig 1: Neural Networks, transformer based LLMs
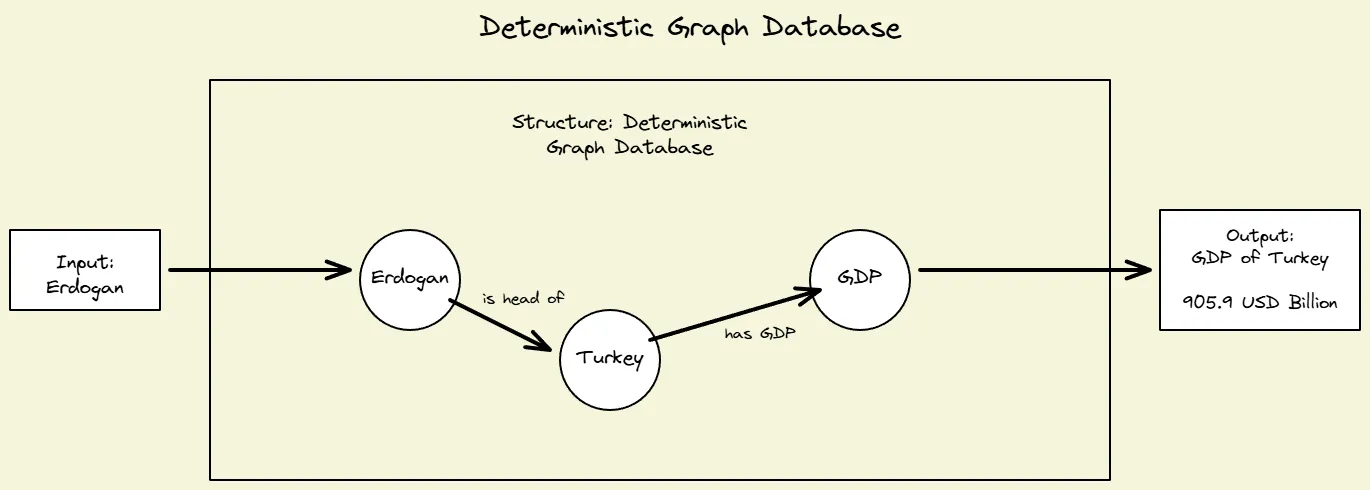 Fig 2: Graph Databases
Fig 2: Graph Databases
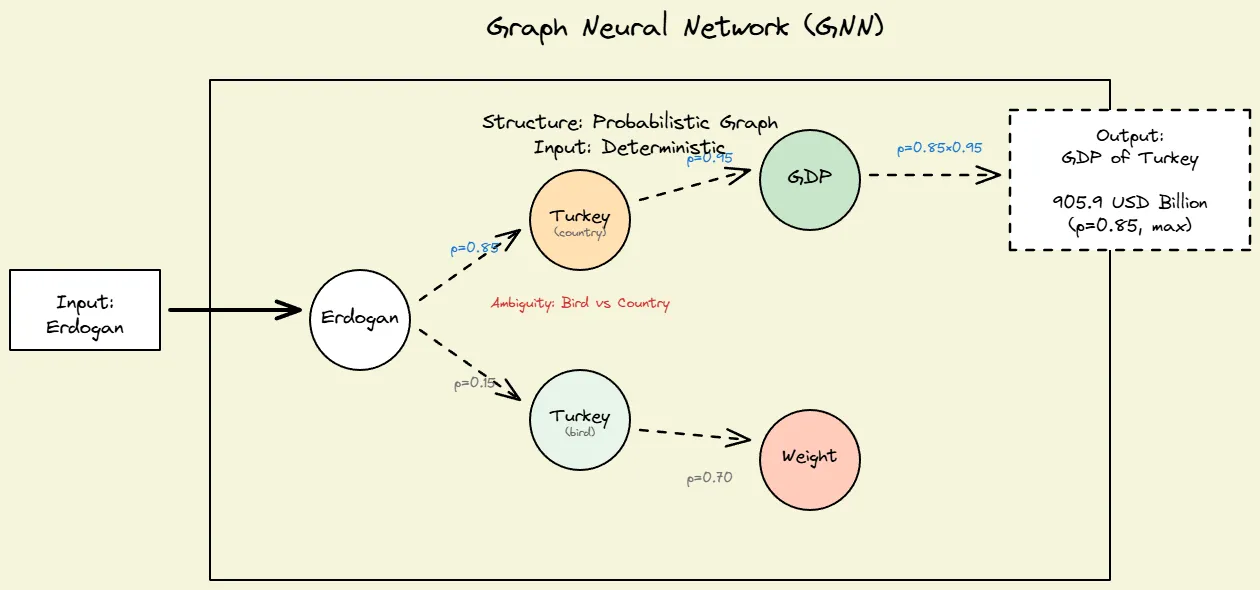 Fig 3: Graph Databases with beam search and/or GNNs
Fig 3: Graph Databases with beam search and/or GNNs
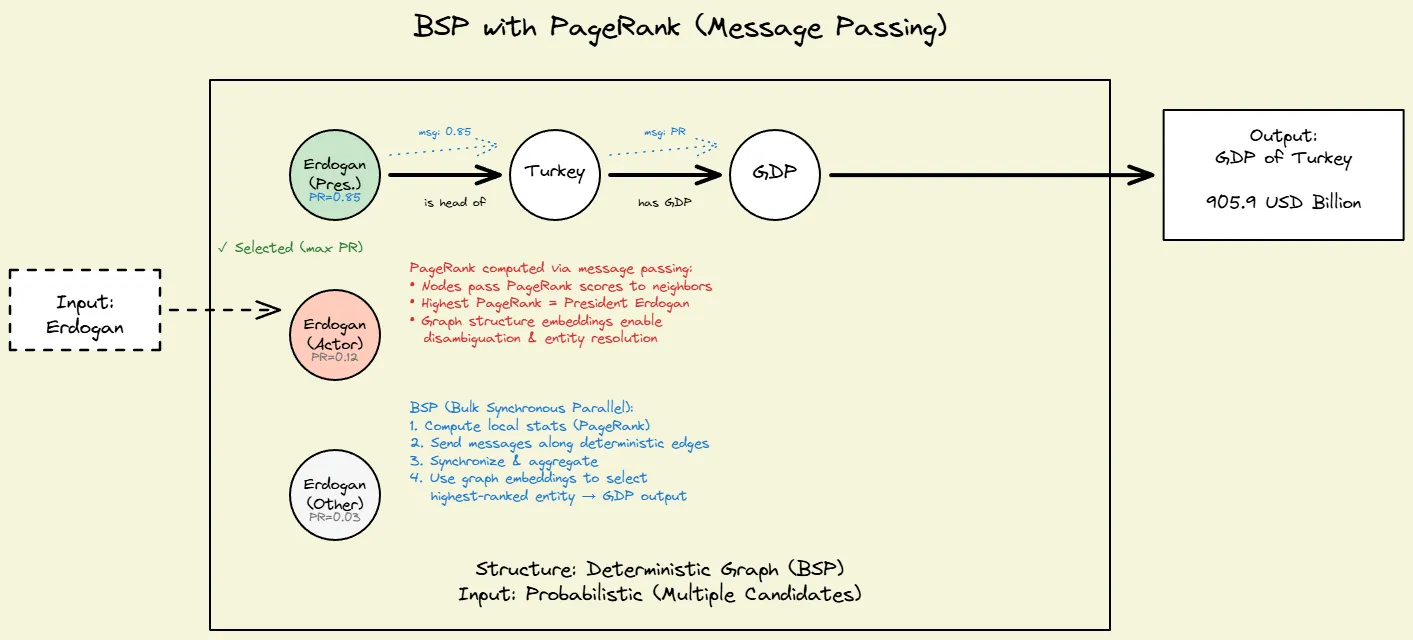 Fig 4: BSP to compute page rank to resolve input probabilistically
Fig 4: BSP to compute page rank to resolve input probabilistically
There’s a deeper reason no single platform spans all four quadrants: each community has standardized on a different in‑memory representation.
| Input | Structure | Community |
|---|---|---|
| Probabilistic | Probabilistic | AI/ML |
| Deterministic | Deterministic | Graph Databases, Graph Mining |
| Deterministic | Probabilistic | PyTorch Geometric |
| Probabilistic | Deterministic | Bulk Synchronous Processing |
They use different data structures. Interfacing with zero-copy is not easy and leads to many inefficiencies.
| Community | Input Data Structure |
|---|---|
| AI/ML | Tensor |
| Columnar Graph Databases | Arrow Memory |
| Graph Analytics | C++ std::vector |
| PyTorch Geometric | Tensor |
| Bulk Synchronous Processing | GraphFrame |
Combining ML and Databases
So how can we do better if we want to emphasize determinism and explainability? One school of thought pushes rigid ontologies and removal of all things probabilistic. But by observing the marketplace they’re NOT doing very well.
For example, consider a medical application trying to classify patient records using a fixed ontology. A rigid hierarchy might define conditions like “diabetes,” “heart disease,” “cancer,” “infection.” But real-world medical records rarely fit neatly into one bucket—a patient with diabetes often has heart disease as a complication. New conditions emerge constantly (e.g., “long COVID” didn’t exist three years ago). Forcing everything into predefined categories either misclassifies patients or requires constant ontology updates by medical experts—a maintenance nightmare.
Therefore we argue that next generation Graph Databases need to facilitate a combination of Deterministic and Probabilistic methods (some call it neuro-symbolic computation) to implement continuous learning approaches that are qualitatively different from the ones being explored today.
This directly impacts retrieval quality. Consider searching for “sugar” in a medical knowledge base. A vector database embedding “sugar” will likely return pages about nutrition, candy, or diabetes—but it will struggle to surface documents about “glucose,” “carbohydrates,” or “insulin” if those terms are distant in the embedding space. More critically, it won’t surface documents about “aspartame” or “sugar substitutes” which are semantically opposite (diets with sugar vs. sugar-free). A graph database with explicit relationships captures all these connections deterministically, regardless of embedding distances.
Ladybug Memory implementation will provide primitives that customers can use to pick and choose the level of determinism and grounding they need. We will of course support the current (LLM) way of doing things and augment it with additional retrieval mechanisms that are desirable in finance, legal and medical fields.
This goes well beyond what GraphRAG-style approaches offer. Those systems use graphs purely for retrieval—adding relationship edges between chunks to improve context selection. Ladybug Memory controls not just retrieval, but the structure of the memory graph itself (what nodes and edges exist, how they’re updated) and the execution semantics of how agents interact with it (transactional updates, consistency guarantees, traversal patterns). It’s a full memory substrate, not just a retrieval enhancement.
We will strive to be a platform provider and work with people building agentic solutions in these domains.
A Path Forward
As long as these memory layouts remain incompatible, we can’t build a single, graph-native memory plane that supports the zero-copy interoperability that continuous, deterministic learning needs.
To bridge this gap, we’re proposing Icebug-Format. It comes in two flavors: Icebug-Disk and Icebug-Memory, both of which represent Graphs as Columnar Sparse Row (CSR) matrices. On disk we’ll use Parquet and in memory we’ll use Apache Arrow.
Efficient interop will be first built between Graph Databases and Graph Compute Platforms. Towards that end, we’re announcing two new projects:
- Icebug - a fork of networkit graph analytics platform. [GitHub]
- Pgembed - an embedded version of postgres + pg_duckdb with many popular extensions for vector and keyword indexing. [GitHub]
A typical agentic deployment will involve multiple agents writing to a shared pgembed instance. Older data will be auto-migrated to columnar format using duckdb. Specialized small models will continuously update a summarized graph in LadybugDB. We will use Icebug as a zero-copy continuous learning platform to discover patterns and update the schema for better explainability, retrieval and compression.
Together, LadybugDB, Icebug, Pgembed and DuckDB aim to give agent builders a unified substrate that spans all four quadrants: probabilistic/deterministic inputs and structures, with a common columnar graph structure underneath both on disk and in memory. We intend to extend this platform to include SparseTensors and GPUs in the future.